As artificial intelligence continues to evolve, audio-driven applications are becoming increasingly central to modern digital experiences. From voice assistants and automated customer support to medical transcription and security systems, high-quality audio data plays a critical role in training robust AI models. At the core of these systems lies audio annotation—the process of labeling and structuring audio data to make it machine-readable.
At Annotera, we understand that accurate and scalable annotation is the foundation of successful AI deployment. As a leading data annotation company, we help organizations unlock the full potential of their audio datasets through precise, customizable, and cost-effective solutions. In this article, we explore the different types of audio annotation—ranging from transcription and classification to more advanced techniques—and their importance in building high-performing AI models.
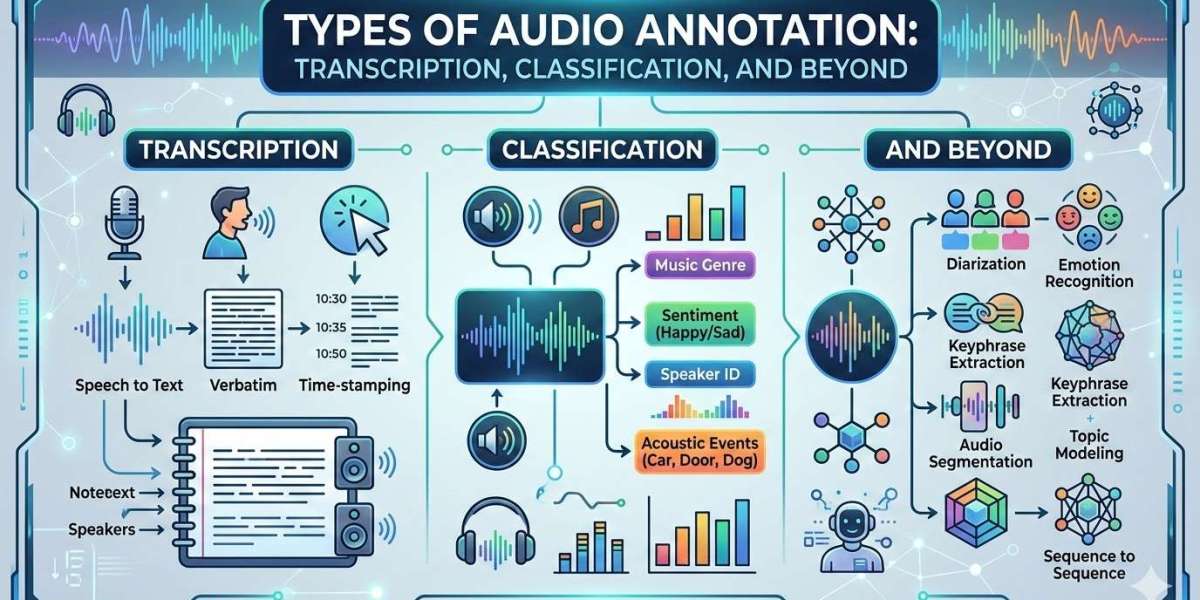
What Is Audio Annotation?
Audio annotation refers to the process of tagging or labeling audio files with relevant information such as text, categories, timestamps, or speaker identities. This structured data is then used to train machine learning models, particularly in domains like automatic speech recognition (ASR), natural language processing (NLP), and sound event detection.
With the increasing complexity of AI applications, organizations often turn to data annotation outsourcing to ensure scalability, quality, and efficiency. Partnering with an experienced audio annotation company like Annotera enables businesses to handle large volumes of audio data while maintaining consistency and accuracy.
1. Transcription Annotation
Transcription is one of the most fundamental types of audio annotation. It involves converting spoken language into written text, making it essential for ASR systems and voice-enabled technologies.
Types of Transcription:
Verbatim Transcription: Captures every word, including filler words (e.g., “um,” “uh”), pauses, and non-verbal cues.
Clean Transcription: Removes unnecessary fillers and focuses on meaningful speech.
Phonetic Transcription: Represents speech sounds using phonetic symbols, often used in linguistic research.
Use Cases:
Voice assistants and chatbots
Call center analytics
Media captioning and subtitling
High-quality transcription requires attention to detail, linguistic expertise, and consistency—qualities that a professional data annotation company ensures through trained annotators and robust quality control processes.
2. Audio Classification
Audio classification involves categorizing audio clips into predefined labels based on their content. Unlike transcription, which focuses on converting speech to text, classification identifies what type of sound is present.
Examples of Categories:
Speech vs. music vs. noise
Environmental sounds (e.g., traffic, rain, sirens)
Emotion detection (e.g., happy, angry, neutral)
Use Cases:
Smart home devices
Surveillance systems
Content moderation
Audio classification is particularly valuable in applications where quick categorization is needed without detailed textual analysis. Many organizations rely on audio annotation outsourcing to handle large datasets efficiently while maintaining labeling consistency.
3. Speaker Diarization
Speaker diarization answers the question: “Who spoke when?” It involves segmenting audio recordings and assigning speaker labels to different portions of the audio.
Key Components:
Speaker segmentation
Speaker identification
Timestamp alignment
Use Cases:
Meeting transcription
Podcast analysis
Legal and forensic audio processing
This type of annotation is crucial for multi-speaker environments and enhances the usability of transcription data by adding contextual clarity.
4. Sound Event Detection
Sound event detection (SED) focuses on identifying and labeling specific events within an audio stream, often with precise timestamps.
Examples:
Gunshots in surveillance audio
Cough detection in healthcare monitoring
Machinery faults in industrial settings
Use Cases:
Public safety systems
Healthcare diagnostics
Predictive maintenance
SED requires highly granular annotation, often combining both classification and temporal segmentation. A specialized audio annotation company ensures that these annotations are both accurate and scalable.
5. Sentiment and Emotion Annotation
This type of annotation goes beyond what is being said to analyze how it is being said. It involves labeling audio based on emotional tone, sentiment, or intent.
Common Labels:
Positive, negative, neutral
Happy, sad, angry, frustrated
Use Cases:
Customer experience analysis
Virtual assistants
Mental health applications
Emotion annotation is complex and often subjective, requiring trained annotators and well-defined guidelines to ensure consistency.
6. Keyword Spotting
Keyword spotting involves identifying specific words or phrases within an audio stream. Unlike full transcription, this method focuses only on detecting predefined keywords.
Examples:
Wake words like “Hey Siri” or “OK Google”
Brand mentions in media monitoring
Use Cases:
Voice-activated systems
Security and surveillance
Marketing analytics
This lightweight annotation approach is ideal for real-time applications where speed and efficiency are critical.
7. Acoustic Feature Annotation
Acoustic feature annotation involves labeling non-linguistic elements of audio, such as pitch, tone, volume, and background noise characteristics.
Use Cases:
Speech synthesis
Emotion recognition
Audio enhancement systems
These annotations are particularly useful for training models that need to understand the nuances of sound beyond just words.
8. Multi-Layered Annotation (Beyond Basics)
Modern AI systems often require a combination of annotation types applied to the same dataset. For example, a single audio file might include:
Transcription
Speaker labels
Emotion tags
Sound event markers
This multi-layered approach provides richer datasets, enabling more sophisticated model training. However, it also increases complexity, making data annotation outsourcing a practical solution for many organizations.
Challenges in Audio Annotation
Despite its importance, audio annotation presents several challenges:
Data Quality Issues: Background noise, overlapping speech, and poor audio quality can affect accuracy.
Scalability: Large datasets require significant time and resources.
Subjectivity: Tasks like emotion annotation can vary between annotators.
Language Diversity: Multilingual datasets require specialized expertise.
A reliable data annotation company addresses these challenges through advanced tools, standardized workflows, and rigorous quality assurance protocols.
Why Choose Annotera for Audio Annotation?
At Annotera, we specialize in delivering high-quality, scalable annotation solutions tailored to your AI needs. As a trusted audio annotation company, we combine human expertise with advanced annotation tools to ensure precision and efficiency.
Our Key Strengths:
Expert Annotators: Trained professionals with domain-specific knowledge
Custom Workflows: Tailored solutions for diverse use cases
Quality Assurance: Multi-level review processes for accuracy
Scalable Operations: Efficient handling of large datasets
Cost-Effective Solutions: Flexible data annotation outsourcing models
Whether you need basic transcription or complex multi-layered annotation, Annotera provides end-to-end support to accelerate your AI development.
Conclusion
Audio annotation is a multifaceted process that goes far beyond simple transcription. From classification and speaker diarization to emotion detection and acoustic analysis, each type of annotation plays a vital role in building intelligent, responsive AI systems.
As audio-based technologies continue to grow, the demand for high-quality annotated data will only increase. Partnering with an experienced data annotation company like Annotera ensures that your datasets are accurate, scalable, and ready to power next-generation AI applications.
By leveraging professional audio annotation outsourcing, businesses can focus on innovation while leaving the complexities of data preparation to experts. In a world driven by voice and sound, the quality of your annotations can make all the difference.








